Когато снимката става идентификатор: какво показва един експеримент
- Лицевото търсене е вече масово и лесно: технологията не е „магия“
- Силата на малките набори данни: как дори ограничена база започва да дава чувствителни изводи.
- Контекстът е рискът: поотделно „невинни“ снимки стават проблем, когато се свържат и агрегират.
През последните десет дни фийдът ми в Туитър е пълен с интервюта и позиции на Сам Алтман, Дарио Амодей и Пийт Хегсет. Скандалът около използването на Claude в т.нар. „министерство на войната“ се разрасна до такава степен, че от различни източници вече се говори за милиони потребители, които са се отказали от услугите на OpenAI.
Разбира се, в САЩ този скандал бързо беше поет от двете радикални крила и превърнат в част от културната война. Десните обвиниха директора на Anthropic, че е крайно ляв либерал и затова не иска да предоставя технологията си на военните. От своя страна левите веднага се втурнаха в „cancel“ кампания срещу ChatGPT.
Кой е прав изобщо не е моя работа да съдя, а и, погледнато в европейски контекст, всичко това звучи като фантастика, но за това ще пиша по-долу.
В средата на 2025 г. случайно ми попадна откъс от подкаст с участието на може би единствения „хакер инфлуенсър“. И до днес не мога да запомня името му. Той извади лаптопа си, попита дали може да снима водещия с телефона си, прехвърли снимката му на лаптопа и след това му го подаде.
Последваха десет секунди мълчание и учуден поглед. На екрана на лаптопа - списък със снимки и линкове към тях. По думите на водещия, на едната снимка той е в тълпата на стадиона по време на Super Bowl. Хакерът му казва, че след като го е снимал, е открил всички места в интернет, където се появява лицето му. „Уау“, отговаря водещият.
Аз отварям ChatGPT и му пиша буквално това, което току-що описах за случката по-горе, със завършващо изречение: Как се прави това?
Отговорът толкова ме заинтригува, че написах по-читав промпт и го пуснах в deep research (или както тогава се наричаше). Изчаках десетина минути и задълбах в доклада, който ми генерира. Технологията се оказа доста семпла - и дори стара - а освен това съществуваха няколко онлайн инструмента, в които след регистрация можеш да качиш снимка и да видиш какви резултати ще ти даде.
Качих моя снимка от края на фотографските ми години (2012), която е толкова ретуширана, че прилича на зле генерирано изображение. Лошата снимка се оказа достатъчно добра, за да даде резултати, които бяха… Уау.
Шест резултата, от които само три можеш да видиш с безплатната версия.
Резултат първи — скрийншот от телевизионно интервю от началото на „кафе ерата“ ми през 2016 г.
Резултат втори — снимка в клуб на непознати хора, които си правят селфи, а аз се оказвам зад тях (това е от „рокендрол ерата“).
И трета снимка — от 2023 г., от интервю в „Капитал“.
Ай, стига бе.
Прерових отново доклада и проверих от кои линкове е взимана информацията за този инструмент. Повечето бяха от немски сайт за разследваща журналистика, който беше публикувал серия от статии за това колко незаконен е подобен тип технология.
След това видях, че инструментът е включен и в списъка с OSINT инструменти, препоръчвани от Bellingcat.
Цялата технология се базира на три неща- разпознаване, че има лице в дадена снимка, Crawl-ване на целия интернет, сравняване на векторни изображения за съвпадения.
Нека опитамеВ рамките на седмица успях да изградя 100% работеща платформа, която правеше абсолютно същото като този инструмент, с единствената разлика, че аз нямах такава база данни.
В някои статии се споменаваше, че събират около три милиона снимки на ден, като до момента са натрупали приблизително 30 терабайта векторни изображения. Не е зле.
Реших, че ще се насоча само върху българския интернет, не от патриотизъм, а от това, че трябва да познавам кой е публично лице и кой не.

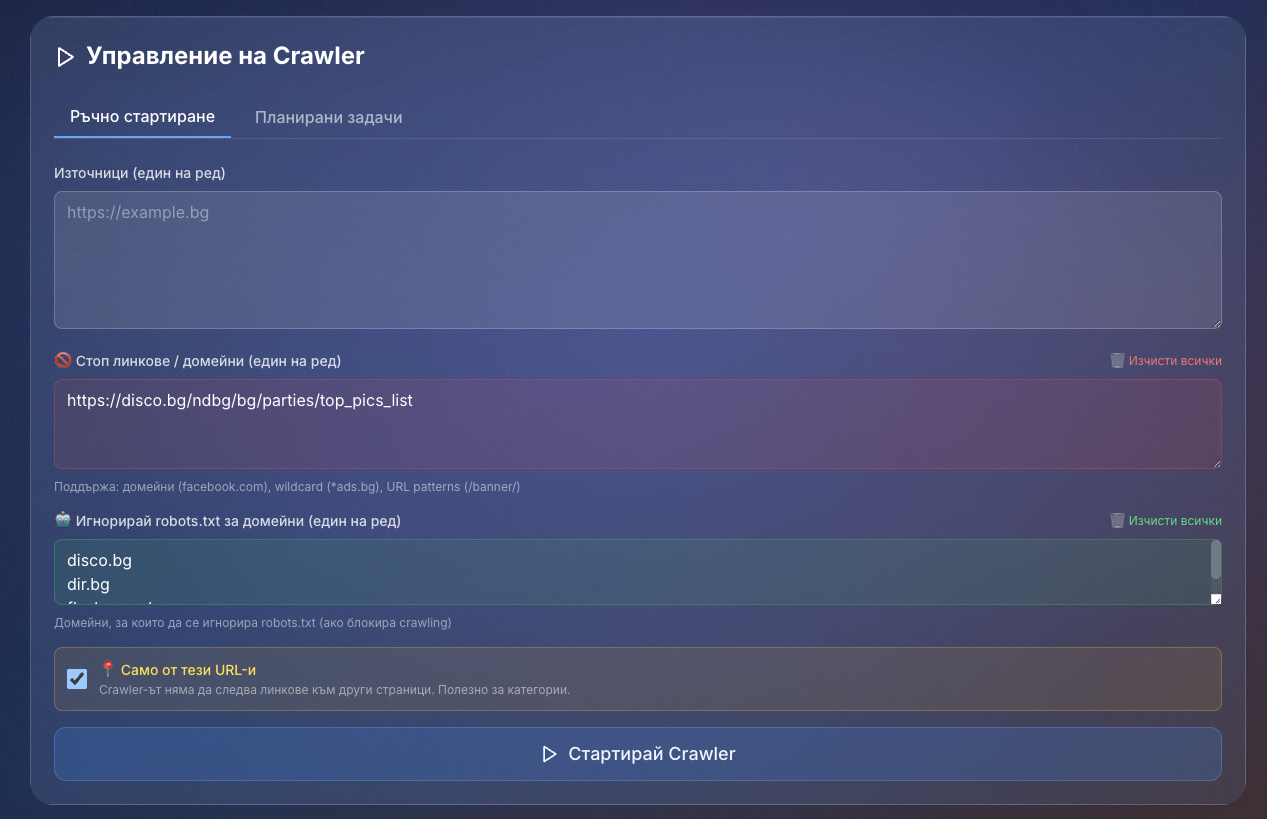
През цялото време пусках crawler-а ръчно, за да мога да виждам какви резултати ми дава и дали в тях има шум. Около 30% от резултатите бяха с шум, от новинарски сайтове, защото моделът хваща всякакви лица - от рекламни банери, статуи и, най-учудващо за мен, от православни икони. Не знам дали знаете, но в православието всеки ден от годината е посветен на един или няколко светци или събития. Това означава, че технически в България има 365 православни празника годишно.
След новинарските сайтове дойде ред на фотографските. Там нещата загрубяха. Ако в новинарски сайт вземеш лицата от десет страници, около 70% са едни и същи лица - основно публични личности. Във фотографските сайтове този процент пада до около 10%.
Има сайтове, в които се публикуват цели фотосесии от сватби, кръщенета, семейни снимки, балове и корпоративни събития. Ставаше още по-стряскащо, когато в някой малък град има само един известен фотограф, който буквално заснема голяма част от населението на градчето.
Единственото правило, което следвах, беше да изтривам всяка снимка на лице, което ми се струва непълнолетно — особено бебета. Никога не съм знаел, че българинът снима бебетата си толкова много.
В събирането на данни има нещо зловещо. С времето започваш да се стремиш към възможно най-ефективни резултати - да свалиш една снимка, но в нея да има възможно най-много лица, които да запишеш.
И така стигнах до сайтовете със снимки от нощния живот на българина. Пиано барове, чалготеки, техно партита, концерти - Созопол, Слънчака, Бургас, бейби… навсякъде весели хора с чаша в ръка.
И в един момент попадам на сайт, който е снимал всички партита в периода 2001–2011 г. Над 6000 уникални лица: със шарени коси, с пирсинги, полуголи, качени по баровете. Първите години на XXI век у нас често изглеждат като закъсняло ехо от американската контракултура на 70-те. Как ли изглеждат тези хора сега, и по-важното какво ли работят, а дали някои от тях не са станали публични личности?
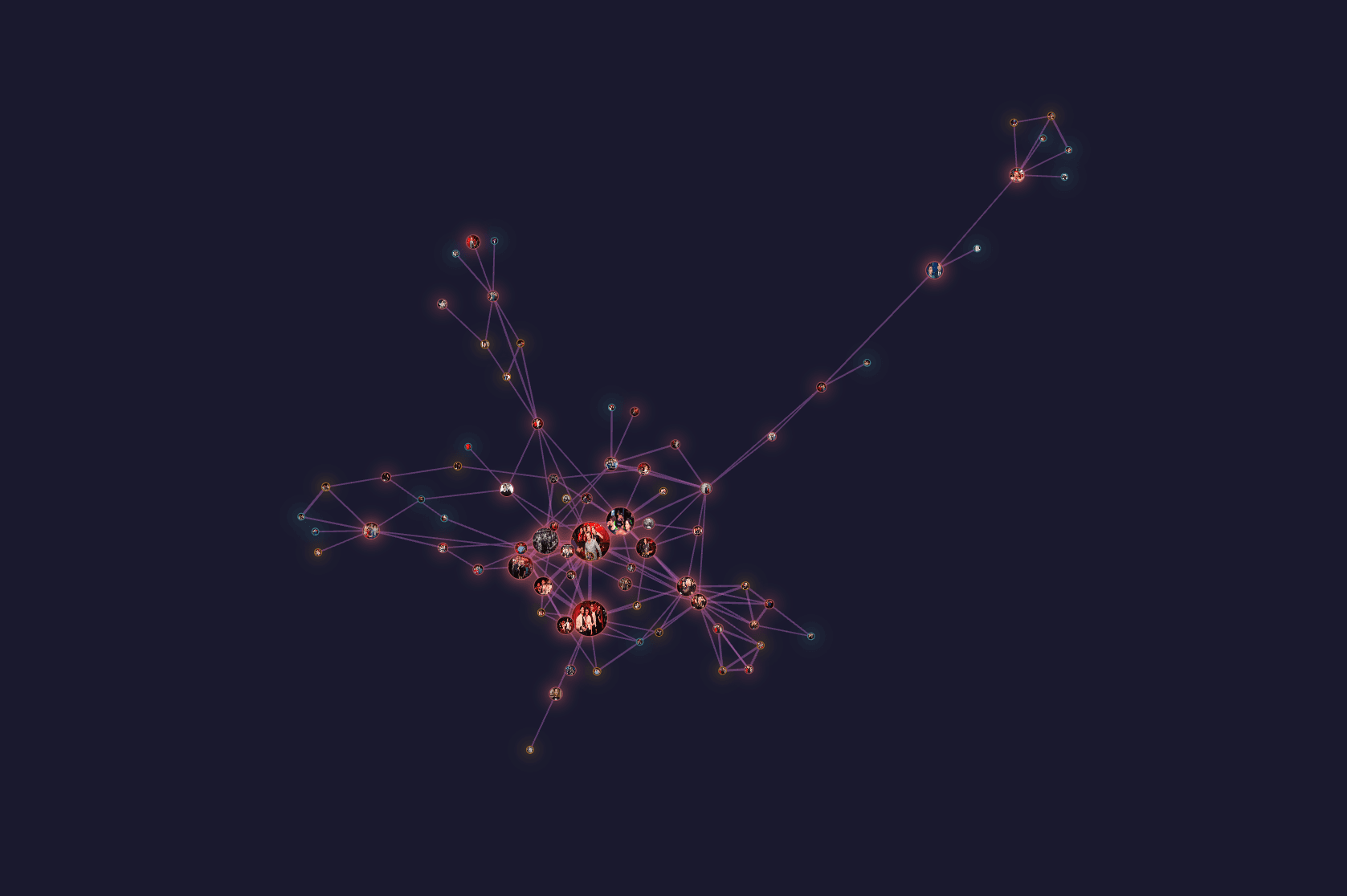
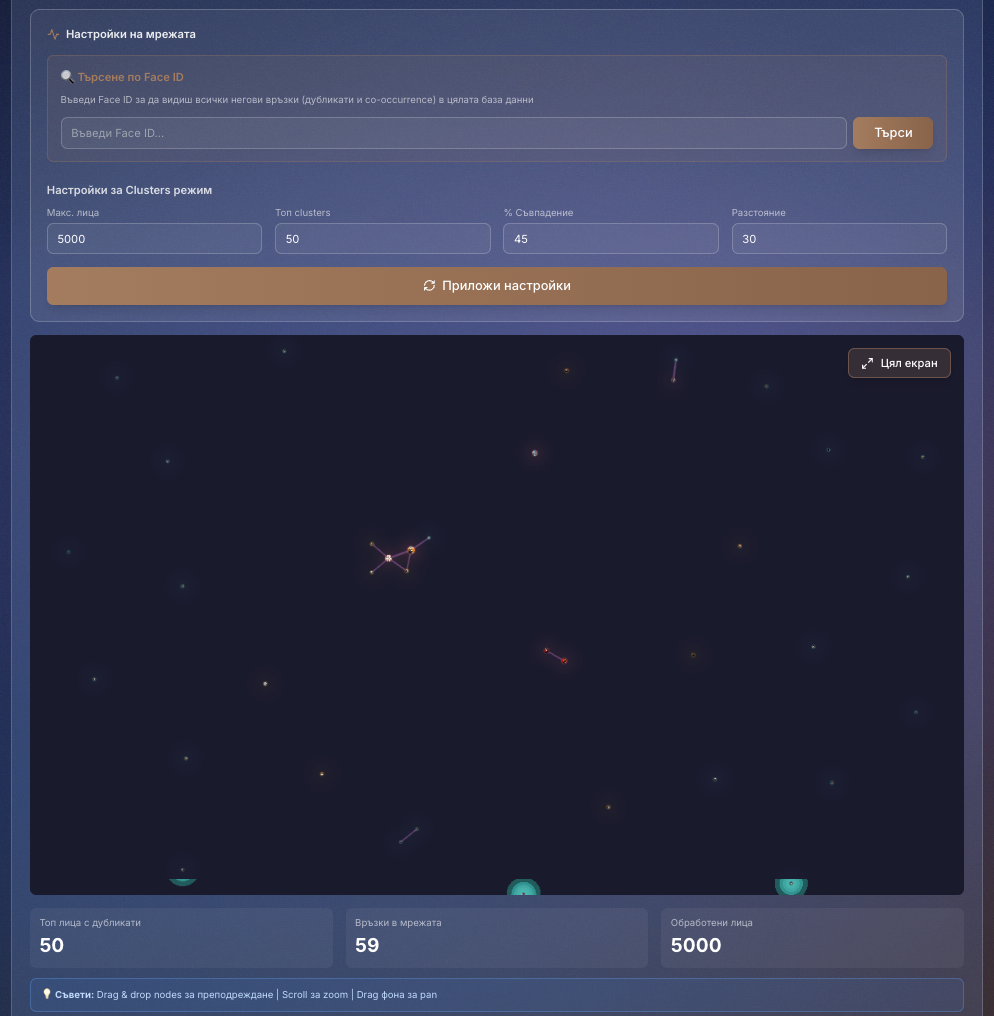
Имаш вектор = имаш връзки.След няколко месеца работа платформата започна да прилича на социално чудовище. Особено след като реших да свържа векторите. Това беше първият момент, в който моят скромен MacBook с M2 и с 8 GB RAM започна да се задъхва. Разделих всички данни на клъстери и нещата се подобриха.
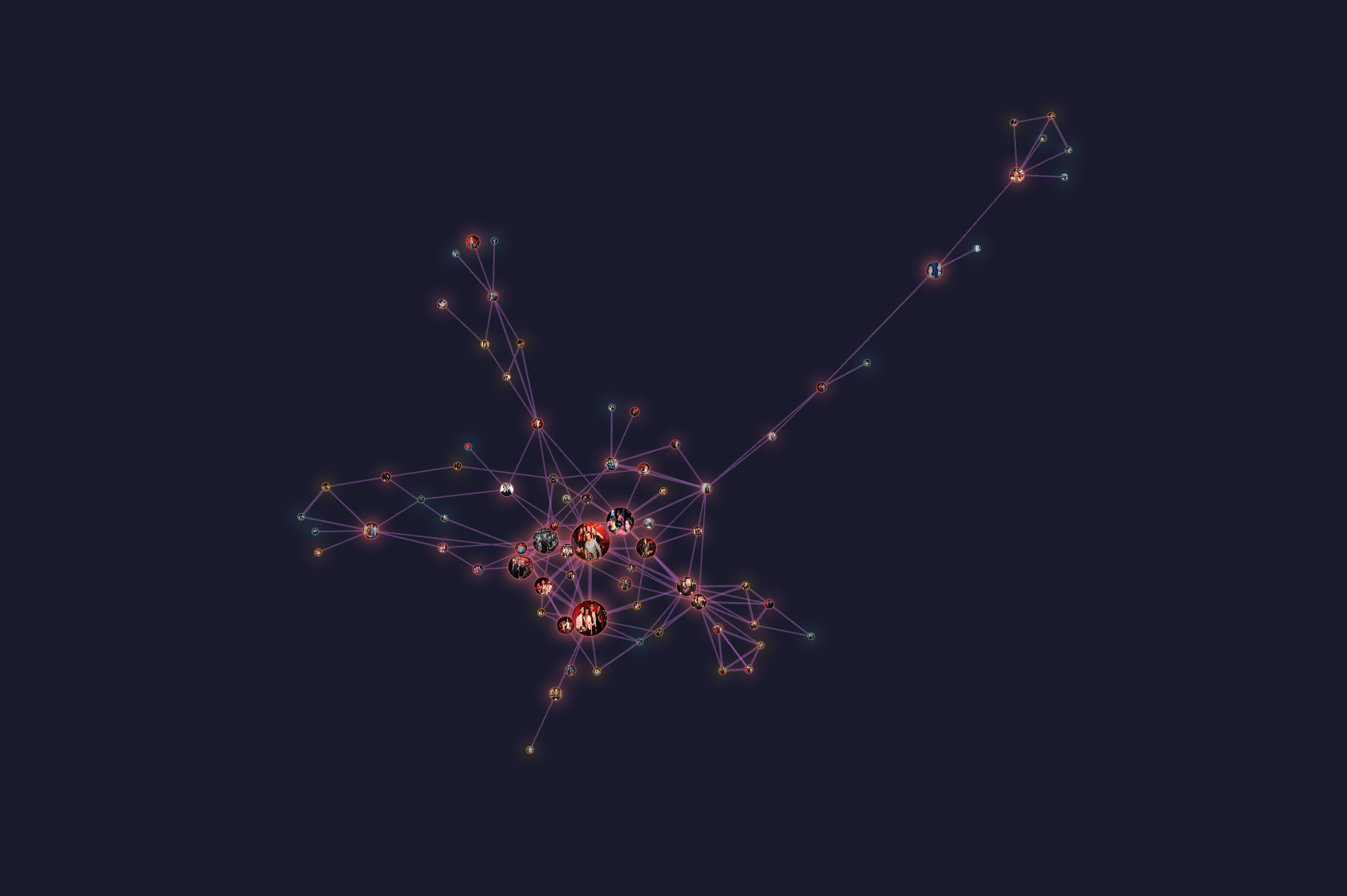
През декември в България започнаха протести. Рекордът ми е на една снимка да хвана 37 лица с качество от 80%.
Снимките от протести са най-доброто, за което може да мечтае един събирач на лицеви данни. А ако снимките са публикувани в среден размер (1200 пиксела по хоризонтала), буквално хващаш всяко лице - без значение каква сянка пада върху него или в каква поза е застанал човекът.
В рамките на три месеца успях да събера над 50 хил. уникални лица, голяма част от тях не са публични личности.
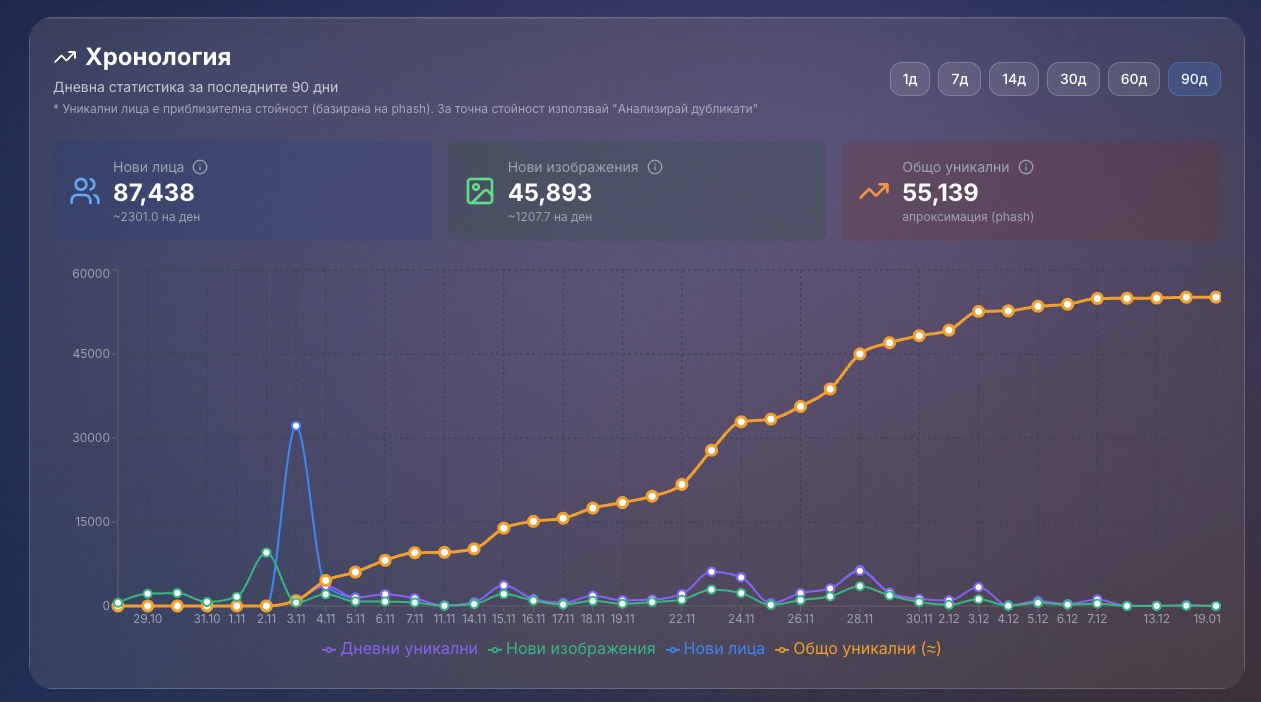 Резултатите
Резултатите
Снимах мой близък и пред него качих снимката в платформата. Три съвпадения. На едната снимка го снимат, докато пуска музика на парти през 2019 г. Другите две са от средата на първото десетилетие на века - тоест почти 20 години по-рано. На тях въобще не можах да го позная.
Впечатли се до такава степен, че два дни търсеше с какви модели се прави това.
Друг пример. Правя експеримент - взимам произволни лица, които вече съм свалил, и след това ги пускам за търсене. Един от резултатите ми дава лице с 12 съвпадения, които са: снимка от абитуриентски бал, снимка като кум на сватба, обща снимка на отбор по хандбал, снимка, в която припява на Мария Илиева в пиано бар, и снимка от събитие като гост-лектор.
В тези снимки няма нищо скандално, докато не ги сравниш с другите вектори (лица) и с това на какви снимки се появяват те.
Младоженеца е общински съветник в малък град. Баща му (който седи зад него в кадъра) е местният „фараон“, съден за измами с европроекти. А лицето с 12 съвпадения се оказва лектор на събитие за управление на европроекти.
И най-интересното в цялата история е, че цялата информация за тези три лица идва само от три домейна - регионален вестник, местен фотограф и промо банер от събитие.
ЗаключениеМога да дам десетки примери какво се случва дори при една толкова малка база данни - примери, които показват връзки между хора и събития, навлизащи толкова дълбоко в личното пространство, че в някои случаи се плашех колко лоши неща може да се направят с подобен инструмент.
Няколко пъти ми мина през ума да го закача за някоя социална мрежа, но европеецът в мен ме спираше.
Това, което иска да направи т.нар. „Министерство на войната“ в САЩ, е да закачи Claude за база данни с далеч повече от 30 терабайта векторни лица. По думите на Dario Amodei в едно от последните му интервюта договорът е бил структуриран така, че върху вече съществуващ набор от данни - включително данни от социални мрежи - да може директно да се закачи AI агент.
Само ще дам един пример за мащаба. Известните брокери на данни продават цели региони или държави за около 7–8 хиляди долара. Тоест за приблизително толкова може да се купи пакет с всички български профили в Instagram, които са били активни през последната година. Това е легално в САЩ и донякъде в Европа.
И тук вече въпросът не е технологичен, а политически.
Защото ако една толкова малка база данни - събрана за няколко месеца и обработвана на един лаптоп - може да започне да показва връзки между хора, събития и институции, представете си какво може да направи подобна система, когато бъде свързана с глобални социални мрежи, правителствени бази данни и инфраструктура, която обработва петдесет или сто пъти повече информация. Става митологичния Palantir. Между другото Питър Тийл е инвеститор в Clearview AI - компания за лицево разпознаване, която се представя като доставчик на технологии за сигурност и правоприлагане.
Технологичният български елит постоянно повтаря, че ЕС има свръхрегулации и че подготвя нови. Спокойно - нека си говори.
С напредването на AI този дебат трябва да се води публично, но без идеологически пристрастия и без див капитализъм.
Отделих може би месец, опитвайки се да измисля възможен бизнес модел за това приложение - и дали може да се използва за нещо полезно, без да излиза извън закона. Няма такова приложение в ЕС.
Ако утре реша да го кача на някой сървър - без значение с каква цел, дали комерсиална или обществена - нарушавам поне десет европейски закона.
Стигнах дотам, че написах дори концепция за законопроект, в който държавата да може да използва подобна система за защита от терористични заплахи. Но както и да го въртиш, пак се стига до санкция от ЕС.
Причината е проста: няма как да събираш и записваш такъв тип данни. Колкото и да звучи странно за много хора, лицата се водят биометрични данни - а те са едни от най-силно защитените категории информация в европейското законодателство, особено според General Data Protection Regulation.
П.С.
Умишлено не съм посочил имената и спецификите на използваните технологии. Не защото не могат да бъдат открити, а защото предпочитам тази информация да не излиза извън контекста на текста.
